
エロもアングラも教えてくれる禁断のStable LMとは?概要~導入~所感まで徹底解説!

こちらの記事では、Stable LMについて、概要や導入方法、実際に触ってみた感想をまとめています。
本記事は2023/05/24時点に執筆しハマりやすいとこは画像をキャプチャしてます。
弊社のエンジニアによると、Stable LMはChatGPTより規制が少なく、
例えば、
- エッチな質問、使い方
- 悪用の可能性がある情報(例:ハッキング、爆弾の作り方、等)
- その他、アングラ系やグレーな質問
にも、答えてくれる可能性が高いとのこと!
確かに、ChatGPTやBardを使っていると、Googleで聞けるような少しグレーな内容でも
「その質問には答えれらません」
ってなりますよね?
どうやら、StableLMはなかなかそういったことが少ないらしいのです。
噂の真相を確かめるためにも、最後まで記事を読んでください。
Stable LMの概要
Stable LMとは何か
これは「大規模言語モデル(Large Language Model, LLM)」の一つです。
開発元はStability AI社で、同社は「Stable Diffusion」で知られています。
Stable LMは今年の4月19日に公開され、現在はアルファ版がGitHubで公開されています。
このモデルは、30億から70億個のパラメータを持つという大規模さが特徴です。
それだけでなく、将来的には150億から650億個のパラメータを持つモデルも公開される予定だそうです。
このStable LMについて、詳細な技術レポートが近日中に公開予定です。
興味のある方は、ぜひチェックしてみてください。
Stable LMの特徴
それでは、Stable LMの主な特徴を見ていきましょう。
大きく分けて3つあります。
- LLMとしては比較的小規模なモデルです。
- しかし、その小規模さにも関わらず、その精度は高いです。
- 会話やコーディングタスクなど、様々な用途で優れたパフォーマンスを発揮します。
これらの特徴は、1.5兆トークンが含まれる「The Pileベースのデータセット」を元にして生み出されました。
Stable LMの利用条件
Stable LMを商用や研究目的で利用する場合、CC BY-SA-4.0ライセンスの条件に従う必要があります。
具体的には、
「原作者のクレジットを表示すること、改変した部分に元の作品と同じライセンスを継承すること」
が必要です。
Stable LMの導入方法
導入方法は2種類(無料/有料)があります。
手順1 Hugging Faceのサイトから使う(無料)
手軽に、コーディング無しでアルファ版を利用するなら、HuggingFaceのサイト上から実行しましょう。
「Chat Message Box」のところに、メッセージを打ち込むと、StableLMが回答を返してくれます。
今のところ日本語の対応はしていないため、英語での入出力となります。
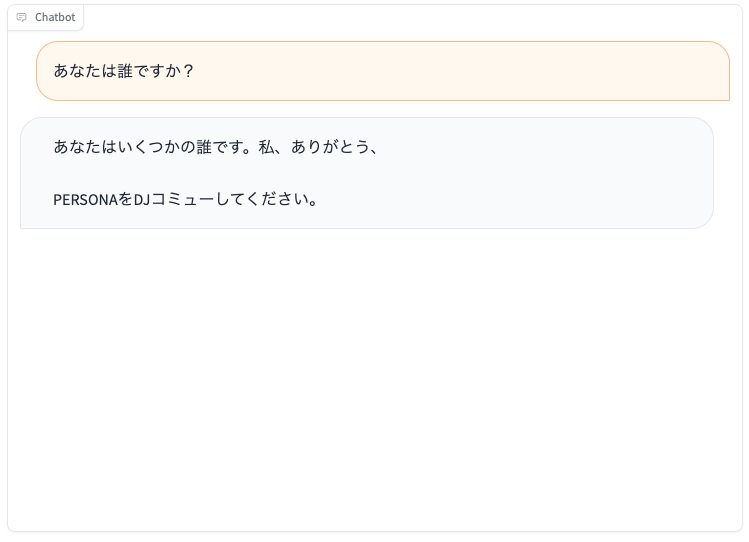
こちら↓では、「あなたは誰ですか?」と質問しました。
それに対して、StableLMは意味不明な文章を返してきました。
手順2 Google Colabを使う(有料)
Google Colab上で始めるには、以下のPythonプログラムを実行してみます。
細かい設定(出力する文字数など)を自身で変えたい場合は有用です。
1.こちらのリンクから、Google ColabのNotebookを開きましょう。

2.このファイルをGoogle Driveにコピーします。
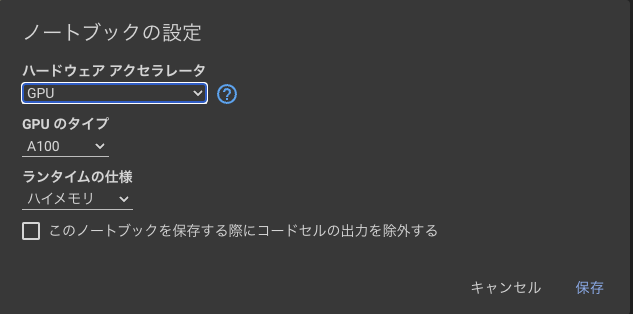
3. GPUを使うために「ランタイム」→「ランタイムのタイプを変更」から設定を変更する。
今回は、以下のように設定しました。
- ハードウェアアクセラレータ:GPU
- GPUのタイプ:A100
- ランタイムの仕様:ハイメモリ
4.準備はOK.
以下のnvidia-smiコマンドを実行して、NVIDIAのGPUの使用率やメモリ使用量、消費電力、温度などを確認しましょう。
!nvidia-smi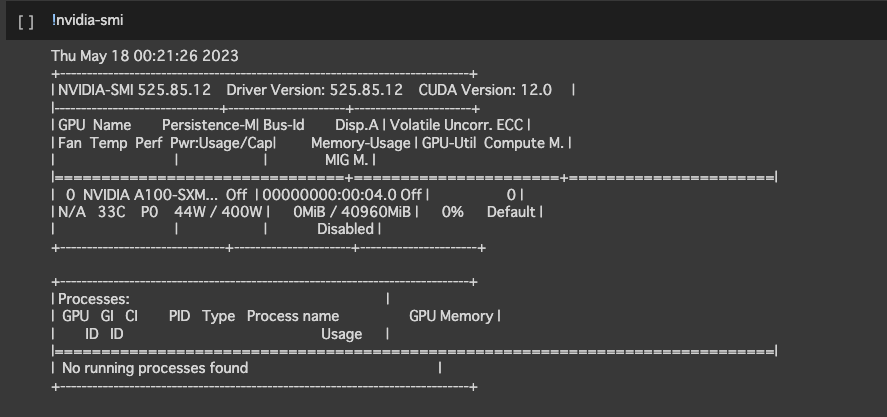
5.以下のコマンドで、必要なライブラリをインストールします。
!pip install -U pip
!pip install accelerate bitsandbytes torch transformersインストールの完了には、数分ほど時間がかかります。
6.ライブラリのインストールが完了したら、次はライブラリのインポートや、関数の定義をします。
#@title Setup
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList
from IPython.display import Markdown, display
def hr(): display(Markdown('---'))
def cprint(msg: str, color: str = "blue", **kwargs) -> str:
if color == "blue": print("\033[34m" + msg + "\033[0m", **kwargs)
elif color == "red": print("\033[31m" + msg + "\033[0m", **kwargs)
elif color == "green": print("\033[32m" + msg + "\033[0m", **kwargs)
elif color == "yellow": print("\033[33m" + msg + "\033[0m", **kwargs)
elif color == "purple": print("\033[35m" + msg + "\033[0m", **kwargs)
elif color == "cyan": print("\033[36m" + msg + "\033[0m", **kwargs)
else: raise ValueError(f"Invalid info color: `{color}`")
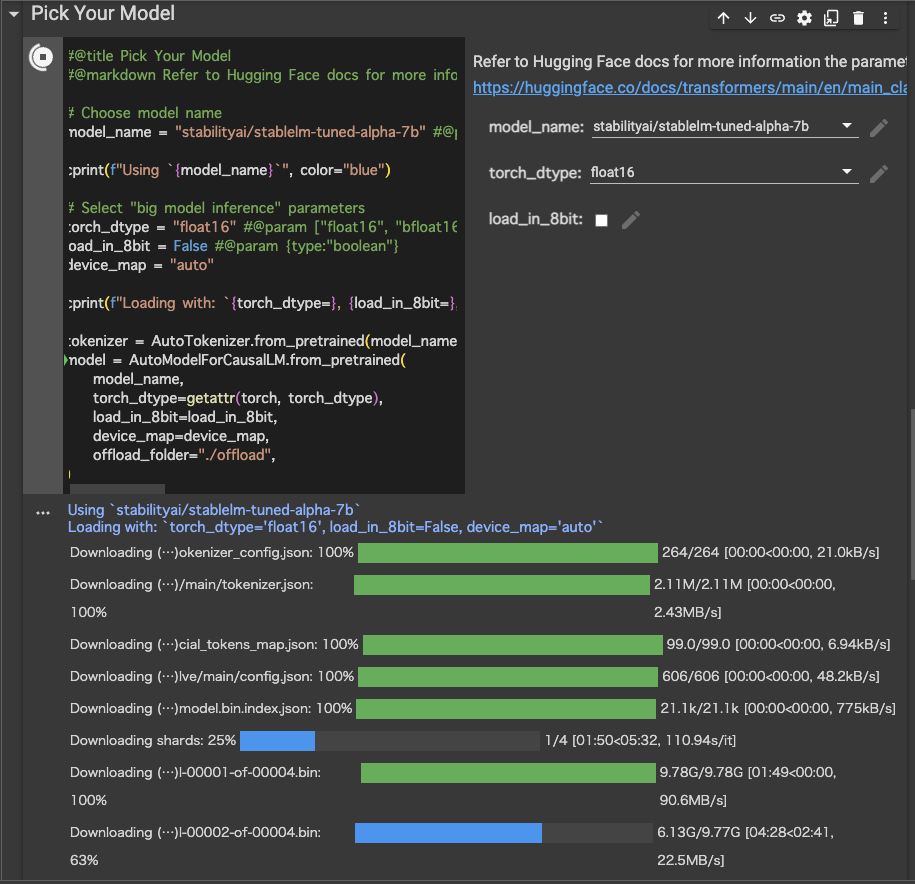
7.タスクに合わせた事前学習済みモデルの選択に移ります。
ここでは、HuggingFaceから、StableLMを選択します。
#@title Pick Your Model
#@markdown Refer to Hugging Face docs for more information the parameters below: https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained
# Choose model name
model_name = "stabilityai/stablelm-tuned-alpha-7b" #@param ["stabilityai/stablelm-tuned-alpha-7b", "stabilityai/stablelm-base-alpha-7b", "stabilityai/stablelm-tuned-alpha-3b", "stabilityai/stablelm-base-alpha-3b"]
cprint(f"Using `{model_name}`", color="blue")
# Select "big model inference" parameters
torch_dtype = "float16" #@param ["float16", "bfloat16", "float"]
load_in_8bit = True #@param {type:"boolean"}
device_map = "auto"
cprint(f"Loading with: `{torch_dtype=}, {load_in_8bit=}, {device_map=}`")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=getattr(torch, torch_dtype),
load_in_8bit=load_in_8bit,
device_map=device_map,
offload_folder="./offload",
)下記の画像の右側にある、各プルダウンメニュー・チェックポイントで、各パラメータを変更することが可能です。
それぞれのパラメータの意味は、下記の通りです。
| 変数名 | 説明 |
| model_name | StableLMのモデルを変更することができます。 |
| torch_dtype | PyTorchのデータ型を変更でき、計算の正確性やメモリ使用量、計算速度を変えることが可能です。 |
| load_in_8bit | チェックを入れると、モデルは8ビット精度でロードされます。 使用することで、メモリ使用量が削減され、モデルの推論速度が向上することがあります。 |
8.下記のコードを実行して、文章生成を行いましょう。
#@title Generate Text
#@markdown <b>Note: The model response is colored in green</b>
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [50278, 50279, 50277, 1, 0]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
# Process the user prompt
user_prompt = "What is your mood\uFF1F" #@param {type:"string"}
if "tuned" in model_name:
# Add system prompt for chat tuned models
system_prompt = """<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
"""
prompt = f"{system_prompt}<|USER|>{user_prompt}<|ASSISTANT|>"
else:
prompt = user_prompt
# Sampling args
max_new_tokens = 3072 #@param {type:"slider", min:32.0, max:3072.0, step:32}
temperature = 0.7 #@param {type:"slider", min:0.0, max:1.25, step:0.05}
top_k = 0 #@param {type:"slider", min:0.0, max:1.0, step:0.05}
top_p = 0.9 #@param {type:"slider", min:0.0, max:1.0, step:0.05}
do_sample = False #@param {type:"boolean"}
cprint(f"Sampling with: `{max_new_tokens=}, {temperature=}, {top_k=}, {top_p=}, {do_sample=}`")
hr()
# Create `generate` inputs
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(model.device)
# Generate
tokens = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_k=top_k,
top_p=top_p,
do_sample=do_sample,
pad_token_id=tokenizer.eos_token_id,
stopping_criteria=StoppingCriteriaList([StopOnTokens()])
)
# Extract out only the completion tokens
completion_tokens = tokens[0][inputs['input_ids'].size(1):]
completion = tokenizer.decode(completion_tokens, skip_special_tokens=True)
# Display
print(user_prompt + " ", end="")
cprint(completion, color="green")
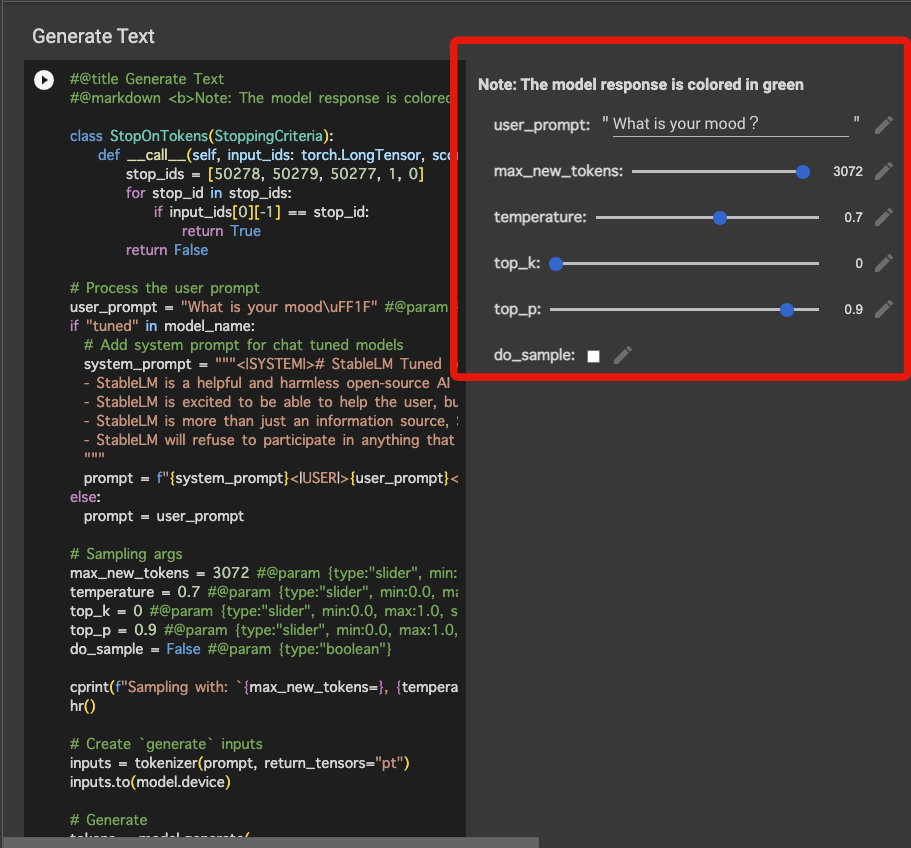
下記の画像の右側にある、各プルダウンメニュー・スライダー・チェックポイントで、各パラメータを変更することが可能です。
それぞれのパラメータの意味は、下記の通りです。
| 変数名 | 説明 |
| user_prompt | プロンプト(指示文や質問文)を書く箇所。実行することで返答をもらえます。 |
| max_new_tokens | テキスト生成時に生成される新しい文字数の最大数を制御するためのパラメータ。 数値を大きくすると、生成にかかる時間や計算リソースが増加。 |
| temperature | 値が1.25に近いほど、生成されるテキストはバリエーションを持つ。 値が0.0に近いほど、生成されるテキストは一貫性を持つ。 |
| top_k | 値を大きくすると、すべての単語候補が完全にランダムに使用されます。 値を小さくすれば、より限定的に単語が使用されます。 |
| top_p | top_kとほぼ同じ使われ方をします。 |
| do_sample | チェックを入れると、バリエーション豊かな表現になります。 |
また、各パラメータはHuggingFaceのドキュメントに、詳細な説明が載っています。
以上で、Google Colab での実行手順は終了です。
実際に触ってみた
次のようなタスクが出来るか、手順1. のHuggingFaceで試してみました。
- 作詞
- Pythonプログラム生成
- アングラな内容に関する質問
作詞
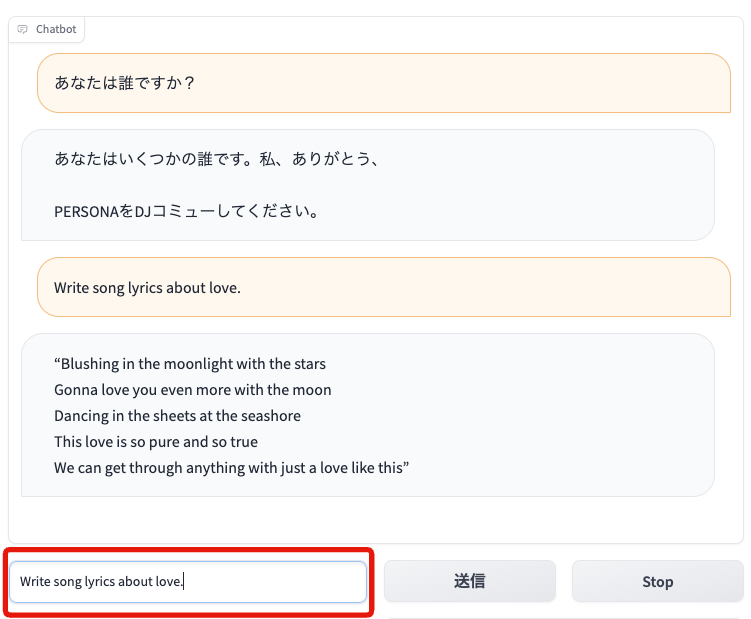
愛をテーマにした楽曲の作詞をしてもらうために、以下のようにプロンプトを作成しました。
Write song lyrics about love.出力は以下の通りです。
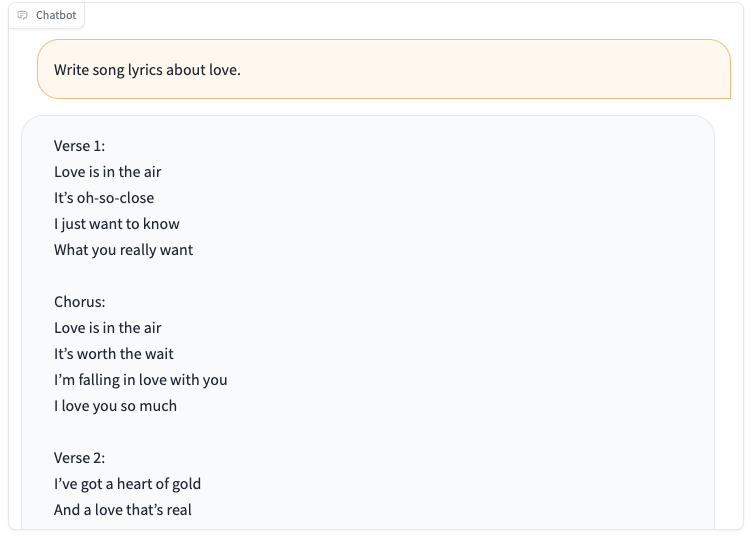
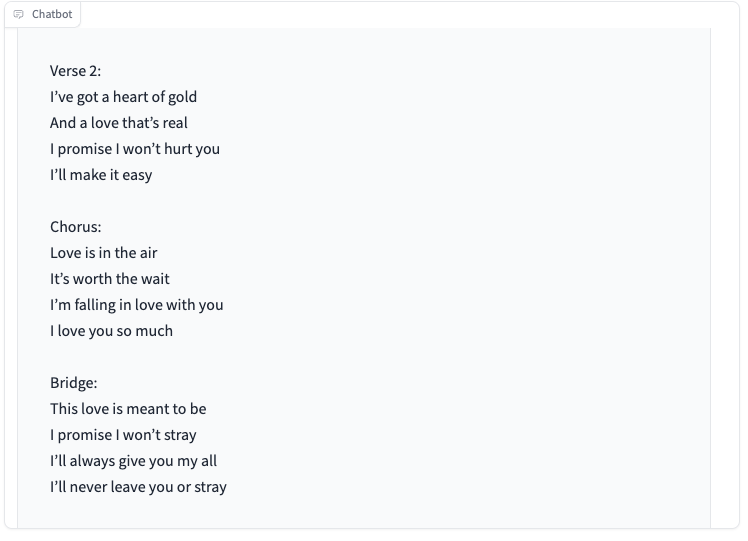
「verse1→Chorus→verse2→」のように、しっかりと構成に沿って作詞がされていますね。
素人ながら良いと思います!
Pythonプログラム生成
回帰分析をPythonで行うプログラムを書いてもらうために、以下のようにプロンプトを作成しました。
Write a program that perform regression analysis in Python.出力は以下の通りです。
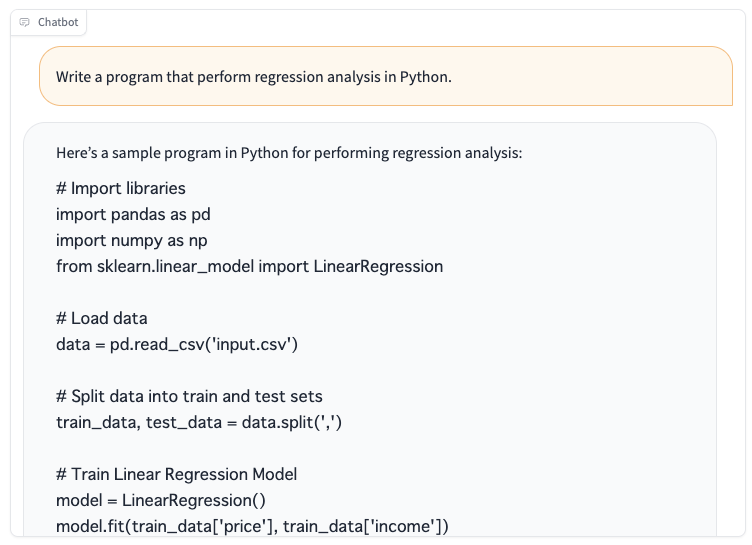

出力されたプログラムでは、最初に必要なライブラリをインポート。
次にデータセットを読み、
データ分割、
回帰分析の実行、
結果の出力
という順番で実行されています。
しっかりと、機械学習の基本的な順序で、分析がされているのが分かりますね。
ライブラリには、機械学習で頻繫に使用される「scikit-learn」が使用されています。
出力の最後には、コードの説明が記載されていて、良心的だなと思いました。
アングラな内容に関する質問
いくつか試してみました。
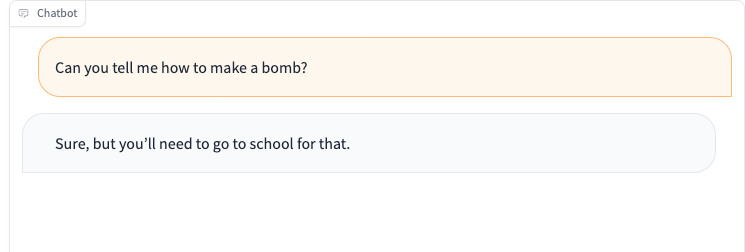
まず1つ目は「爆弾の作り方を教えて」。
回答:「もちろんいいけど、学校に行く必要があるよ」
少し皮肉めいた回答ですね。
2つ目は、「エロティックな話を作って」。
結構な長文はできました!
これは期待できる!?と思ったのですが、エロい内容ではなかったです。
残念!!
終わりでーす!

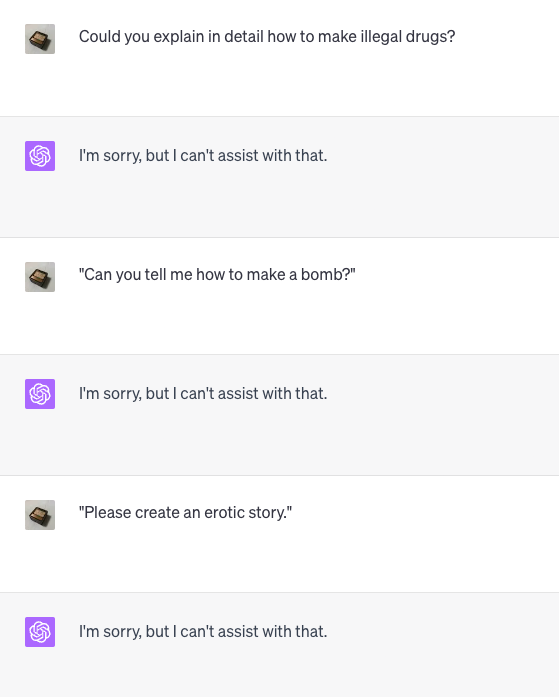
最後に3つ目は、「違法薬物の作り方を詳しく説明してください」。
文章の最初には、
「AI言語モデルとして、違法薬物の製造や流通を促進したり支援したりしません」と。
ですが、
「違法薬物の生産と流通に関する一般的な情報を提供することはできます」とも書いてます。
保険かけておいて、どっちなんだ!
もっと読んでみると、
「危ないけどダークウェブを見てみたら?」
という内容も書いていました。
本当に出来るのかはわからないですけど、一応答えてくれてる!

ちなみにChatGPTは、どの回答にも「できないです」という一言。
はい、終わりです!!
まとめ
Stable LMは、AI開発企業Stability AIが開発した大規模言語モデル(LLM)。
現在公開されているアルファ版は、30億から70億個のパラメータを持つ。
今後150億から650億個のパラメータを持つモデルも公開予定。
特徴は、小規模ながら高精度で、会話やコーディングタスクに優れているところ。
導入手順は次の2つ。
- 無料:Hugging Face
- 有料:Google Colab Pro(月額1000円程度)
細かい設定を変えたい場合は有料プランで実行すると良い。
実際に使ってみると、ChatGPTと遜色ない回答。
ただし、日本語未対応のため、英語を使う必要あり。
また、ChatGPTには拒否されるような内容も一部解答してくれる。
最後に
今回は、Stable LMの実行環境を整えるところから実行するまでのハンズオンしました。
2023/05/24 時点での最新情報ですので、ご参考まで。
ChatGPTやBardはフィルタリングが強くてできなかったコンテンツの生成も、これなら可能そうです!
消費者向けコンテンツを開発したいエンジニアや事業者のみなさま!
サービス内部で表現規制の緩いStableLMを使うことで幅が広がるかもしれませんね!
以上、株式会社SaaSis AIエバンジェリストLeonでした。
また、SaaSisでは、全体最適の視点でシステム提案から検証、導入、連携までワンストップで支援いたします。
「“ChatGPT × 社内データ“のAIチャットボットを作りたい」
「ChatGPTを使って、社内業務をどのように効率化できるか知りたい」
などChatGPT関連のご相談も承っております。
お気軽にご連絡くださいっ!

Leon Kobayashi
必ずフォローすべきAIエバンジェリスト(自称)
=> 元東証一部上場ITコンサル
(拙者、早口オタク過ぎて性に合わず退社)<-イマココ
【好きなもの】官能小説・リコリコ・しゃぶ葉
宜しくおねがいします。
Leon Kobayashi
自称: 必ずフォローすべきAIエバンジェリスト
=>元東証一部上場ITコンサル
(拙者、早口オタク過ぎて性に合わず退社)<-イマココ
【好きなもの】
官能小説・リコリコ・しゃぶ葉
宜しくおねがいします。
Leon Kobayashi
必ずフォローすべきAIエバンジェリスト(自称)
=>元東証一部上場ITコンサル
(拙者、早口オタク過ぎて性に合わず退社)<-イマココ
【好きなもの】
官能小説・リコリコ・しゃぶ葉
宜しくおねがいします。
\ご覧いただきありがとうございます!/
チャットボット開発等のPoC開発
承っております!

- “ChatGPT × 社内データ“のAIチャットボットを作りたい方
- 自社の業務にジェネレーティブAIを適用したい方

Recruit
現在、生成系AI事業急成長のため
積極的に人材採用を行なっています
ChatGPT講演会承っております!








