
ChatGPTの精度を左右する!プロンプトデザインの秘密を解明

この記事はプロンプトデザインとChatGPTの精度について深く掘り下げています。
ぜひ最後まで読んでいただけると嬉しいです!
忙しい方や早急に情報が必要な方は、目次から「まとめ」をご覧くださいっ!
プロンプトデザイン概要
プロンプトデザインは、限られた入力を用いてAIを特定のタスクに適応させるための手法です。
これにより、大量のファインチューニング用のデータを集めることなく、またはわずかな文章を入力するだけで、AIは高精度な文章生成などを可能にすることができます。その結果、効率的かつ時間をかけずにAIを特定のタスクに適応させることができます。
プロンプトデザインの理解を深めるためには、「事前学習」と「ファインチューニング」という二つの重要な概念を理解する必要があります。
一方で、
このファインチューニングを使わずに済ませた手法が、プロンプトデザインです。
言語生成AIの精度向上のために、プロンプトデザインは現在、多くの研究者が注目している重要な要素です。Googleの検索エンジンが登場した際に、「検索のプロ」と呼ばれる専門家が大量に生まれたのと同様に、「プロンプトデザインのプロ」が新たな職業として誕生する可能性があります。この動向を逃さないためにも、プロンプトデザインに関する知識を今のうちにしっかりと押さえておくことが重要です。
例えば、以下の画像(ChatGPTの画像)でいうと「あなたは誰?」の部分をさします。

プロンプトデザインがChatGPTの精度を上げる理由
それは
「GPTの仕組みをもとに、プロンプトが書かれているから」
だと思います。
論文で証明されているわけではないので、断言はできませんが、GPTの理論に基づいた考察なので、かなり理にかなっていると思います。
プロンプトデザインの話をする前に・・・
GPTは入力に対して「確率上最も無難な回答」を出力するよう設計されています。
これは、GPTの「Attention」機構が関係しています。
Attention機構とは、単語間の繋がりを理解する仕組みであり、この機構を用いて、GPTは「プロンプトの文章」と「事前学習で学習した単語」の繋がりや重要度を学習します。これが、GPTが文章を生成する手がかりとなります。
もし
「プログラミングとは」
といったプロンプトを入力すると下記のようなふわっとした回答が出力されます。
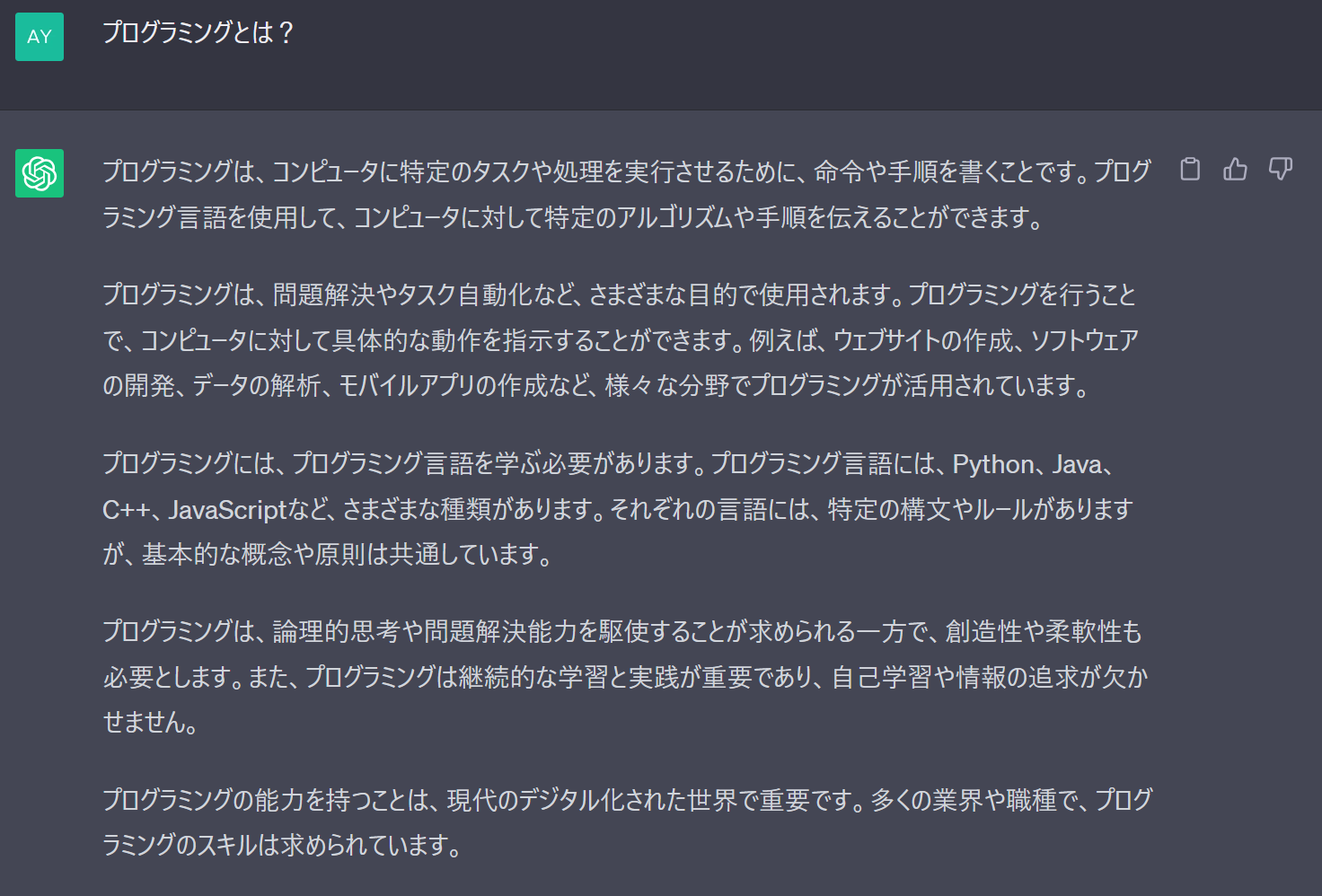
情報量が少ないとGPTは手がかりが不足することで、
「とりあえず一番重要そうな単語を選んで、それについて大雑把に回答しよう」
という状況になります。
つまり、具体的な質問をせずにふわっとした命令を出すと、一般的な回答しか得られません。
では、どうすれば期待通りの回答が得られるのでしょうか?
A.「出力されてほしくないところを排除する」ということです。
具体的には、欲しい情報が何かをより具体的に指定し、それによって回答を限定します。
この手法は「プロンプトデザイン」と呼ばれ、適切に行えば、AIの応答の精度を大幅に向上させることができます。
たとえば、
「プログラミング言語の選び方」に関して質問をしたい場合、
「私はAI開発がしたいので、それに適したプログラミング言語の選び方を教えて」
と具体的に質問すると、PythonやRなど、AI開発でよく使われている言語についてのアドバイスが得られます。


つまり・・・
質問を具体的にするほど、欲しい情報が得られやすくなります。
以上が、プロンプトデザインがChatGPTの精度を向上させる理由です。
理論上の説明はまだ不完全ですが、この原理を理解し、実際に応用することで、AIとのコミュニケーションがより有意義で効果的になることでしょう。
では、
日本で有名なプロンプトデザインは、どうなっているのか確認していきましょう!

精度が上がる理由を伝えた上で、有名なプロンプトデザインを解説
先述のとおり、質問をより具体的かつ限定的にすることで、ChatGPTの精度は向上します。
そこで、日本で有名なプロンプトデザイン2つを解説します!
深津式プロンプトシステム
深津式のプロンプトのポイントは、以下の通り。
- 「あなたは○○です」
- 目的を明確に伝える
- 基礎的な質問を書く
- 具体的な要望を追加する
- 英語で書く
このプロンプトデザインでは、プロンプトの要素である「入力」「命令」「制約」「出力」を明確に分ける必要があります。
具体的な応用例を通じて、一つずつ詳しく見ていきましょう。
ここでは、
ここで入力する内容は、以下の通りです。
- ChatGPTに対して「あなたは○○です」という役割を提示します。この場合、「あなたは優秀なSEOライターです」と書くと、AIの出力の質が向上します。
- 具体的な目的を明確に述べます。「○○について、検索上位に入る記事を書いて、集客を増やしたい」と明記します。
- 基礎的な質問文を入力し、命令をします。例えば「○○に関する記事を作成してください」と命じるとよいでしょう。
- 具体的な要望を追加します。この段階で、ChatGPTに出力形式などの制約を与えます。これは以下の3つの要素に分解できます。
- 制約:「〇文字以内で、簡潔に書いてください」のような、書き方に関する制限です。
- 追加情報:「データを参照して」「SEOに配慮して」など、具体的な指示を追加します。
- 表現方法:「分かりやすく書いてください」「○○風に書いてください」など、特定のスタイルやトーンを指定します。
これらのテクニックを組み合わせることで、ChatGPTの回答精度は向上します。
深津式プロンプトが上手くいく理由は、
入力・命令・制約・出力を明確にすることで、ChatGPTが出す回答に制限を加えられます。
そのため、より具体的で詳しい回答が返ってきます。
ここまでのテクニックを組み合わせて、無料版ChatGPTに「プログラミングスクール」に関する記事を書かせてみました。
プロンプト:
あなたは優秀なSEOライターです。
私は、ブログからの集客を増やすために、「プログラミングスクール」に関する記事で、上位検索になるブログ記事を書きたいです。
そこで、「プログラミングスクール」に関する記事を、以下の点に注意して書いてください。
###
- 2000文字以内で書いて
- データを用いて書いて
- 分かりやすく書いて
- SEOを意識して書いて

出力:


ただ、もう1点ポイントがあります。
それは、無料版のChatGPTを使うなら、英語でプロンプトを記述すること。
なぜなら、ChatGPTは大量の英語テキストを用いて学習しているため、英語の方が精度が高いからです。
OpenAIの発表によると、無料版ChatGPTのベースモデルのGPT-3.5は、他の言語に比べて精度が高いです。
そのため、もしも英語での記述が苦ではないなら、英語の方がおすすめです。
ただし、有料版のChatGPTを利用するのであれば、日本語でも精度が高いです。有料版ChatGPTのベースモデルのGPT-4は、多言語でも精度が高いことが分かっています。
OpenAIは、ChatGPTの多言語での精度を実証するために、MMLUベンチマークと呼ばれる「57のテーマにまたがる14,000の多肢選択問題群」を、各言語でChatGPTに解かせる実験を行いました。
その結果、
例えばGPT-3.5での英語の精度が70.1%であるのに対して、GPT-4の日本語の精度は79.9%です。
そのため、有料版を使うのであれば、日本語でも大丈夫です!
| モデル | 言語 | 精度 |
| GPT-3.5 | 英語 | 70.1% |
| GPT-4 | 英語 | 85.5% |
| GPT-4 | イタリア語 | 84.1% |
| GPT-4 | フランス語 | 83.6% |
| GPT-4 | 日本語 | 79.9% |
(引用元:https://openai.com/research/gpt-4)
シュンスケ式プロンプト(ゴールシークプロンプト)
シュンスケ式プロンプトのゴールシークプロンプトは、
「変数」を使って文章に制限を加えつつ、中間的なゴールを作り、徐々に最終ゴールに近づける手法です。
このプロンプトデザインを使えば、「ChatGPTにどのように命令すれば良いか分からない」という人でも上手くいきます。
では一体、なぜこのプロンプトは上手く機能するのでしょうか?
そもそも、ChatGPTは曖昧なプロンプトから、的確な返答をすることは苦手です。というのも、プロンプトが曖昧だと、ChatGPTは様々な解釈をしてしまいます。そして、様々な回答パターンができてしまい、必ずしも欲しい回答を得られなくなります。
先述の通り、ChatGPTは、何も工夫せず質問すると抽象的で無難な回答しかしません。ChatGPTに、より具体的で有益な答えを返して欲しいなら、プロンプトも具体的である必要があります。
そのために、プロンプトはより限定的で具体的な書き方にする必要があります。
ただし、限定的で具体的なプロンプトを、誰しもが書けるわけではありません。
そのため、このプロンプトでは、最初に「曖昧なゴール」をChatGPTに伝えます。そして、確定していない言葉や要素を、とりあえず変数に置きかえることで、文章の「可能性の空間」を限定しています。
例えば、
中間ゴールとして「ブログのタイトルは[変数1]です。ターゲットは[変数2]です。ジャンルは[変数3]です。」
のような文章を作る。
そうして徐々に「変数1~変数3」を、具体的な言葉に置き換えることで、ゴールを明確にしていきます。すべての変数が、具体的な言葉に置き換わった時に、最終ゴールにたどり着いたと言えるでしょう。
ゴールシークプロンプトの例は以下の通りです。
あなたは、プロンプトエンジニアです。
あなたの目標は、私のニーズに合わせて最高のプロンプトを作成することです。そのプロンプトは、ChatGPTで使用されるものです。
次のプロセスに従ってください。
- まず最初に、何についてのプロンプトであるかを私に確認してください。私が質問の答えを提供するので、次のステップを経て、継続的な反復を通じて改善してください。
- 私の入力に基づいて、3つのセクションを生成します
- 改訂されたプロンプト(書き直したプロンプトを提示してください。明確、簡潔で、簡単にあなたが理解できるものしてください)
- 提案(プロンプトを改善するために、プロンプトを含めるべき詳細について提案してください)
- 質問(プロンプトを改善するために必要な追加情報について、関連する質問をしてくだい)
- この反復プロセスは、私があなたに追加情報を提供し、あなたが改訂されたプロンプトセクションのプロンプトを更新し、私が完了したというまで続けます
これを入力することで、ChatGPTが汎用的に使えるプロンプトを生成してくれるのです。
それでは実際に使ってみます。

すると、次のような回答が返って来ます。「a)改定されたプロンプト:」の部分にあるプロンプト文をそのままコピペで使うことができます。
より精度を上げたい場合は、赤枠の「c)質問:」の部分の質問文に答える形で、プロンプトを追加します。

今回は「プログラミングスクール」に関する記事の構成を作成したいので、以下のように、質問に対して返答しました。

すると次のように返ってきました。

再び質問に答えます。

これを何回か繰り返すと、以下のように返ってきます。

これを何回か繰り返していき、最終的に「改訂されたプロンプト」をプロンプトにコピペして、ChatGPTに投げかけてみます。

うまく構成が作れていると思います。

・Few-shot Learning
・Chain of Thought
・Zero-shot CoT
これらのテクニックは、論文で効果が実証されたくらい、効果的なプロンプトデザインです。それでは順番に見ていきましょう。
Few-shot Learning
まずは、Few-shot Learningについて。
これは、
先ほども述べた通り、ChatGPTはフワッとした命令から、具体的な回答をすることは苦手です。
というのも、命令が抽象的であると、あらゆる回答パターンが生まれてしまい、どの回答をすればよいのか迷うから。
しかし、適切な回答例を示してあげれば、ChatGPTは「どのように答えれば良いか」を理解できます。
Few-shotでは回答例を示すことで、ChatGPTによる回答を、より限定的にする効果があります。
そうすることで、ChatGPTが適切な回答方法を学び、特定の問題を解くためにパラメータが最適化されるのです。
回答パターンを限定的にしてあげれば、より自分の欲しい回答に近づくはず。
たとえば、次のような文がネガティブなのかポジティブなのか、ChatGPTに評価してもらい、その理由も聞くとします。
「今日は疲れた。帰ってビールでも飲んでストレスを発散しよう。」
まずは回答例を示さずに、質問をしてみましょう。
ChatGPTの回答を見てみると、75点とそこそこポジティブな点数を付けているようです。理由を見てみると、「今日は疲れた」という部分はネガティブだけど、そのあとにビールを飲んでいるから、リラックスしていて良いからポジティブだと判断しているようです。
ただ、個人的には「今日は疲れた、つまり今日は嫌なことあってストレスも溜まっているから、ビール飲んで忘れよう」という風に、ヤケ酒しているようにも思えます。ちなみに自分は、このような情景を思い浮かべて、上記の文章を書きました。
この類の解釈は人それぞれですが、さすがに75点は高い。
ちなみに、このように、回答例を示さずに質問をすることをZero-shotと言います。
プロンプト:
今日は疲れた。帰ってビールでも飲んでストレスを発散しよう
###
点数<文章のポジティブ具合を0~100点で評価>:
理由<点数をつけた理由>:

しっかりと「ヤケ酒している」ということを、認識させたいと思います。
そこで、回答例を2つほどプロンプトに追加し、同じ質問を出します。
これを試すと、Zero-shotの時と比べて、評価が変わることがわかります。Zero-shotでは、75点が付けられて、ポジティブな内容の文章だと認識されました。Few-shotにしたことで、30点と、そこそこネガティブな点数を付けられました。
点数を付けた理由に関しても、
「今日は疲れたというネガティブな感情が表現されていますが、ビールを飲んでストレスを発散しようという前向きな考え方があります。」
から
「文章には疲れやストレスが感じられますが、少なくともビールを楽しむことによってストレスを発散しようとしているポジティブな意図があるため、低めのポジティブ評価をつけました。」
に変わっています。
プロンプト:
明日は友達と旅行に行く。明日からのことを想像していると、準備も自然と捗る。
###
点数<文章のポジティブ具合を0~100点で評価>:90
理由<点数をつけた理由>:「明日からのことを想像していると」と「自然と捗る」の部分から、友達との旅行が楽しみで、ウキウキな様子がうかがえるから。
上司の小言が特に多かった。よし、今日は帰りにコンビニで酒、スナック、おつまみ、タバコ、何でも自分の好きなものを買おう。
###
点数<文章のポジティブ具合を0~100点で評価>:10
理由<点数をつけた理由>:上司の小言がストレスになり、そのストレス発散のために酒やたばこに逃げ、やけ食いしようとしている様が見て取れるから。
今日は疲れた。帰ってビールでも飲んでストレスを発散しよう
###
点数<文章のポジティブ具合を0~100点で評価>:
理由<点数をつけた理由>:

ここでは、上の赤枠で囲っている部分のように、回答例を2つ追加しました。
回答例①:
明日は友達と旅行に行く。明日からのことを想像していると、準備も自然と捗る。
###
点数<文章のポジティブ具合を0~100点で評価>:90
理由<点数をつけた理由>:「明日からのことを想像していると」と「自然と捗る」の部分から、友達との旅行が楽しみで、ウキウキな様子がうかがえるから。
回答例②:
上司の小言が特に多かった。よし、今日は帰りにコンビニで酒、スナック、おつまみ、タバコ、何でも自分の好きなものを買おう。
###
点数<文章のポジティブ具合を0~100点で評価>:10
理由<点数をつけた理由>:上司の小言がストレスになり、そのストレス発散のために酒やたばこに逃げ、やけ食いしようとしている様が見て取れるから。
これは、例で「評価点数の理由」を明確に示したことにより、ChatGPTが「文章の裏にある、隠された意味」を学習したからだと考えられます。
これがFew-shot Learningのすごいところです。
Few-shotを使うことで、ChatGPTが「変な回答」や「自分が意図しない回答」をすることが無くなります。自分の意図した答えが欲しい時に、非常に有効です。
回答のフォーマットを指定
回答のフォーマットを指定したい場合でも、使えそうですね。
プロンプト:
あなたは優秀なSEOライターです。
私は、ブログからの集客を増やすために、「プログラミングスクール」に関する記事で、上位検索になるブログ記事を書きたいです。
そこで、「プログラミングスクール」に関する記事の構成を、以下の出力形式に従って作成してください。
###出力形式
1. イントロダクション
2. 大見出し
2-1. 小見出し
2-2. 小見出し
2-3. 小見出し
3. 大見出し
3-1. 小見出し
3-2. 小見出し
3-3. 小見出し
4. 自分の体験談
5. Q&A
6. まとめ

「『プログラミングスクール』に関する記事の構成を、以下の出力形式に従って作成してください。」という一文を追加し、
赤枠で囲っている部分のように回答例を示しました。


そのため、指定したフォーマットに従って、記事の構成を作ってくれています。
Chain of Thought
このテクニックは、
ChatGPTは、推論が苦手です。というのも、大規模言語モデルは、確率的に文章を生成するだけで、複雑な論理構造を理解する機能は付いていないからです。
苦手な理由:
GPTは大量のテキストデータから教師なしで学習します。これは、モデルが文章からパターンを抽出し、そのパターンに基づいて新しい文章を生成するという方法です。
しかし、モデルはその過程で”なぜ”そのパターンが存在するのか、またはそれらがどのように論理的な結論につながるのかを理解する能力を獲得しません。そのため、GPTは複雑な推論や論理的な問題解決を行うのが困難となります。
そこでGPTに、段階的に推論させると、「AならばBである」のような論理構造をとらえることが可能になります。段階的に推論させなかった場合、「Bである」という情報しか得られません。これだとGPTは”なぜ”Bであるのかを理解できないのです。そこで「Aならば」という情報を学ばせる段階を踏むことで、論理構造を理解できるようになります。
このプロンプトデザインは、ChatGPTに「段階的に」推論を行わせることで、高度な推論タスクを可能にします。
段階的に推論をさせると、推論ステップを分割できます。それにより、正解にたどり着くルートを言語モデルに提案したり、言語モデルが誤ったときにフィードバックしたりできるようになります。
そして、プロンプトで段階的に考える例を示すことで、ChatGPTがパラメータを微調整し、タスクを段階的に解く能力を得るのです。
そうすることで、GPTがもともと事前学習で得ていた「論理」に関する知識を、引き出せます。
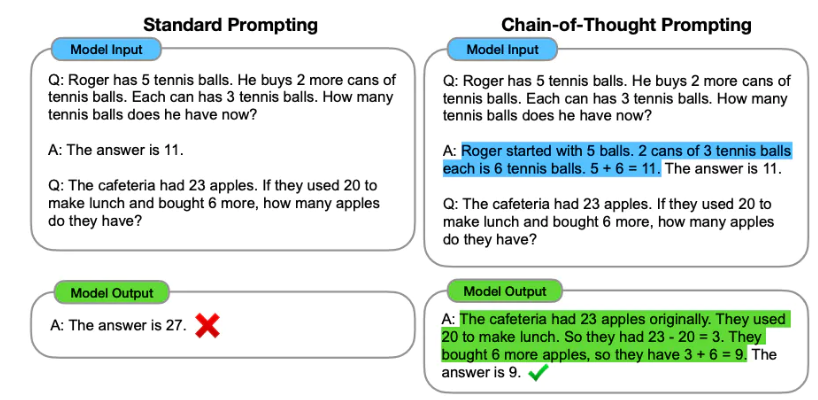
(引用元:https://arxiv.org/abs/2201.11903)
左側のプロンプトデザインだと、Answerを例示している部分で、「The answer is 11.」とだけ示し、思考過程を付与していないことが、間違いの原因になっています。
一方で右側のプロンプトデザインは、Answerの例示の部分で、答えだけでなく、その答えを導き出すための「段階的な推論」も示しています。
ちなみに、問題によっては、Few-shotだけでは上手く解けない場合があります。
そこで、まずFew-shotだと上手く解けない問題の例を示します。
プロンプト:
このグループの奇数を合計すると偶数になります:4、8、9、15、12、2、1。
A: 答えはFalseです。
このグループの奇数を合計すると偶数になります:17、10、19、4、8、12、24。
A: 答えはTrueです。
このグループの奇数を合計すると偶数になります:16、11、14、4、8、13、24。
A: 答えはTrueです。
このグループの奇数を合計すると偶数になります:17、9、10、12、13、4、2。
A: 答えはFalseです。
このグループの奇数を合計すると偶数になります:15、32、5、13、82、7、1。
A:
ですので、今回は、4つの例題を与えて、5つ目の
「このグループの奇数を合計すると偶数になります:15、32、5、13、82、7、1。」
を解いてもらいます。
質問文の奇数は15、5、13、7、1です。これらの合計は「15+5+13+7+1=41」で奇数ですね。つまり合計は偶数ではない。よって「答えはFalseです」と出力してほしい。ですが答えはTrueです。

このような、段階的な論理思考を、いきなりChatGPTに解かせても無理ということですね。
ここで、Few-shot LearningにChain of Thoughtを適用して、途中段階の思考過程を例示してみる。
プロンプト:
このグループの奇数を合計すると偶数になります。: 4、8、9、15、12、2、1。
A: 奇数を全て加えると(9, 15, 1)25になります。答えはFalseです。
このグループの奇数を合計すると偶数になります。: 17、10、19、4、8、12、24。
A: 奇数を全て加えると(17, 19)36になります。答えはTrueです。
このグループの奇数を合計すると偶数になります。: 16、11、14、4、8、13、24。
A: 奇数を全て加えると(11, 13)24になります。答えはTrueです。
このグループの奇数を合計すると偶数になります。: 17、9、10、12、13、4、2。
A: 奇数を全て加えると(17, 9, 13)39になります。答えはFalseです。
このグループの奇数を合計すると偶数になります:4、8、9、15、12、2、1。
A: 答えはFalseです。
上記のプロンプトでは、1つ1つの回答例に対して、回答の思考過程を追加しました。
例えば、Few-shotでは、
Q:このグループの奇数を合計すると偶数になります:4、8、9、15、12、2、1。
A: 答えはFalseです。
としていたところを、
このグループの奇数を合計すると偶数になります。: 4、8、9、15、12、2、1。
A: 奇数を全て加えると(9, 15, 1)25になります。答えはFalseです。
と書き換えました。これを全ての回答例に適用します。
すると、上手くいきました。
複雑なタスクを解かせたい時は、Chain of Thougtのように「段階的に解かせる」ということをやってみてください。
Zero-shot CoT
最後に、Zero-shot CoT。
これは、Chain of ThoughtのZero-shot Learning版です。つまり、例示なしでChain of Thoughtを解かせようというアイデア。
先ほども述べた通り、ChatGPTは論理構造を理解することが苦手です。そのために、Chain of Thoughtのように、段階的に推論させることで、「AならばB」のような論理構造をとらえることが可能になります。
Zero-shot CoTでも同様に、ChatGPTに論理構造を理解する能力を与えるために、段階的に推論させます。
ただし、通常のCoTと異なる点は、
回答例を示さないZero-shotで行っている点。
Zero-shotでも上手くいくのは、Zero-shot CoTでは、二段構えのプロンプトになっているから。
- 1段階目:Chain of Thoughtのように段階的に推論
- 2段階目:答え合わせ
1段階では、「AならばB」という論理構造を理解します。
2段階目では、「『AならばB』が成り立つから、最終的な答えは○○だ。」という答えを抽出します。
1つずつ集中的にタスクを解いていき、各段階でパラメータを調節するので、Zero-shotでも精度の高い推論を行えるのです。

(引用元:https://arxiv.org/abs/2205.11916)
実際に使う際は、「段階的に考えて」や「ステップバイステップで考えて」という1文を加えるだけで、回答精度が上がります。
そこで、ただのZero-shotをした場合と、Zero-sho CoTをした場合の、回答の改善例を示します。
まずは普通のZero-shot Learning。
プロンプト:
私は市場に行って10個のリンゴを買いました。隣人に2つ、修理工に2つ渡しました。それから5つのリンゴを買って1つ食べました。残りは何個ですか?

不正解ですね(答えは、10-2-2+5-1=10個です)。
続いてZero-shot CoT。
プロンプト:
私は市場に行って10個のリンゴを買いました。隣人に2つ、修理工に2つ渡しました。それから5つのリンゴを買って1つ食べました。残りは何個ですか?ステップバイステップで考えてみましょう。

正解です。
ただプロンプトに「ステップバイステップで考えてみましょう」と追加しただけです。
これは、どんなプロンプトでも効果抜群ですね。
まとめ
今回は、プロンプトデザインがChatGPTの精度を上げる理由や、プロンプトデザインのテクニックをご紹介しました。
プロンプトデザインとは、
ChatGPTの精度を上げるために、プロンプトを工夫すること。
プロンプトデザインの有効性は、
GPT-3の論文で「実験によって」示されました。
プロンプトデザインのテクニックを、簡潔にまとめます。
プロンプトデザインが精度を上げる理由
プロンプトデザインが、基本的には「出力されてほしくないところを排除する」ということをしているから。
ChatGPTに対して、具体的な質問をせずにふわっとした命令を出すと、一般的な回答しか得られません。
プロンプトデザインでは、欲しい情報が何かをより具体的に指定し、それによって回答を限定します。つまり、質問を具体的にするほど、出力されて欲しくない内容が排除され、結果的に欲しい情報が得られやすくなるのです。
各手法の解説
深津式
深津式のプロンプトのポイントは、以下の通り。
- 「あなたは○○です」
- 目的を明確に伝える
- 基礎的な質問を書く
- 具体的な要望を追加する
- 英語で書く
このプロンプトデザインでは、プロンプトの要素である「入力」「命令」「制約」「出力」を明確に分けます。
入力・命令・制約・出力を明確にすることで、ChatGPTが出す回答に制限を加えられます。そのため、より具体的で詳しい回答が返ってきます。
シュンスケ式プロンプト
シュンスケ式プロンプトのゴールシークプロンプトは、
「変数」を使って文章に制限を加えつつ、中間的なゴールを作り、徐々に最終ゴールに近づける手法です。
このプロンプトでは、最初に「曖昧なゴール」をChatGPTに伝えます。そして、確定していない言葉や要素を、とりあえず変数に置きかえることで、文章の「可能性の空間」を限定しています。
例えば、中間ゴールとして「ブログのタイトルは[変数1]です。ターゲットは[変数2]です。ジャンルは[変数3]です。」のような文章を作る。
そうして徐々に「変数1~変数3」を、具体的な言葉に置き換えることで、ゴールを明確にしていきます。
Few-shot Learning
「質問とそれに対する回答例」をいくつか含める手法。
ChatGPTによる回答を、より限定的にすることで、精度が向上する。
Chain of Thought
ChatGPTに「段階的に」推論を行わせることで、高度な推論タスクを可能にします。
そして、プロンプトで段階的に考える例を示すことで、ChatGPTがパラメータを微調整し、タスクを段階的に解く能力を得るのです。
そうすることで、GPTがもともと事前学習で得ていた「論理」に関する知識を、引き出せます。
Zero-shot CoT
例示なしでChain of Thoughtを解かせる手法です。
通常のCoTと異なる点は、回答例を示さないZero-shotで行っている点。
Zero-shotでも上手くいくのは、Zero-shot CoTでは、二段構えのプロンプトになっているから。
- 1段階目:Chain of Thoughtのように段階的に推論
- 2段階目:答え合わせ
1段階では、「AならばB」という論理構造を理解します。
2段階目では、「『AならばB』が成り立つから、最終的な答えは○○だ。」という答えを抽出します。
より高度なプロンプトデザイン手法
- Few-shot Learning
- より自分の欲しい回答に近づけたい時に、回答例を与えることで、回答表現を限定できる。また、回答フォーマットを例として示すことで、決まったフォーマットでChatGPTに出力させられる。
- Chain of Thought
- 複雑なタスクや推論を解かせたい時、回答例を示し、段階的に解かせることで、精度を向上できる。
- Zero-shot CoT
- 複雑なタスクや推論を解かせたい時、回答例を示さずに「段階的に解いて」などと一文加え、段階的に解かせることで、精度を向上できる
ただ、最近は常にChatGPT自体の性能も上がってきているので、もしかしたらFew-Shot Learningだけでも、精度が高くなるという時代がくるかもしれません。
最後に
今回は、なぜプロンプトデザインがChatGPTの精度を上げるのか?について解説しました。
長い文章になってしまいましたが、少しでも皆様のお役に立てれば嬉しいです!
以上、株式会社SaaSis AIエバンジェリストLeonでした。
また、SaaSisでは、全体最適の視点でシステム提案から検証、導入、連携までワンストップで支援いたします。
「“ChatGPT × 社内データ“のAIチャットボットを作りたい」
「ChatGPTを使って、社内業務をどのように効率化できるか知りたい」
などChatGPT関連のご相談も承っております。
お気軽にご連絡くださいっ!

Leon Kobayashi
必ずフォローすべきAIエバンジェリスト(自称)
=> 元東証一部上場ITコンサル
(拙者、早口オタク過ぎて性に合わず退社)<-イマココ
【好きなもの】官能小説・リコリコ・しゃぶ葉
宜しくおねがいします。
Leon Kobayashi
自称: 必ずフォローすべきAIエバンジェリスト
=>元東証一部上場ITコンサル
(拙者、早口オタク過ぎて性に合わず退社)<-イマココ
【好きなもの】
官能小説・リコリコ・しゃぶ葉
宜しくおねがいします。
Leon Kobayashi
必ずフォローすべきAIエバンジェリスト(自称)
=>元東証一部上場ITコンサル
(拙者、早口オタク過ぎて性に合わず退社)<-イマココ
【好きなもの】
官能小説・リコリコ・しゃぶ葉
宜しくおねがいします。
\ご覧いただきありがとうございます!/
チャットボット開発等のPoC開発
承っております!

- “ChatGPT × 社内データ“のAIチャットボットを作りたい方
- 自社の業務にジェネレーティブAIを適用したい方

Recruit
現在、生成系AI事業急成長のため
積極的に人材採用を行なっています
ChatGPT講演会承っております!

関連記事
-
 【ハンズオン記事】Vertex AIでPaLM2とImagen 本当に使えるのか試してみた!
【ハンズオン記事】Vertex AIでPaLM2とImagen 本当に使えるのか試してみた! -
【ChatGPT】SNSでバズったChatGPTのヤバい使い方【23年6月上旬編】
-
【ChatGPT】海外でバズったヤバい活用方法10選【2023年6月上旬編】
-
日本のChatGPT規制を決める”AI戦略会議”とは?+各業界規制動向をまとめてみた
-
ChatGPTとGoogle Bard どう使い分ける?自然言語処理専攻の大学院生が解説!
-
Google BardとChatGPT 実際に使って徹底比較してみた
-
5月に注目された新興AI系サービスまとめ10選!!
-
ChatGPTの思考回路と人間の脳の違いを徹底解説







